When selecting the algorithms or tunning the hyperparameters we want to generalize as much as we can. A simple approach would be to divide again the training set into training and validation. The training part will be used to test different algorithm or hyperparameters to later be checked against the validation set. By doing this we face the possibility for our algorithm to overfit the training data.
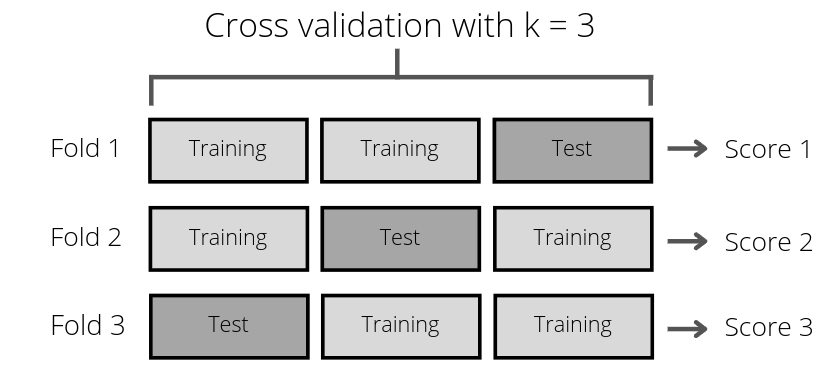
Cross validation is a technique to avoid the above problems. Instead of dividing the training dataset into training and validation, the training dataset will be split into k groups. Then, we will perform k iterations where each algorithm and hyperparameter will be trained with k-1 subgroups and validated against the last subgroup. With this method, we can avoid the algorithms to overfit the same training data each time leading to incorrect results.
# Import sklearn cross_val_score function
from sklearn.model_selection import cross_val_score
# Import from sklearn support vector machine algorithm
from sklearn import svm
# SVM instance with hyperparameters kernel and C set
clf = svm.SVC(kernel='linear', C=1)
# Test with cross-validation (k=5) metric results
# (training = X, validating = y).
scores = cross_val_score(clf, X, y, cv=5)