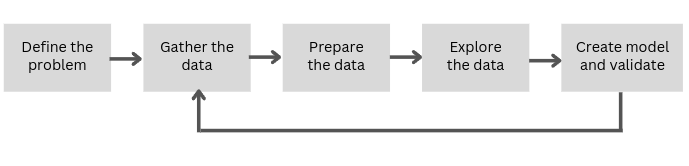
I find it common for everybody, starting with data science problems, to skip all the basic steps and move forward to create new models immediately. To resolve this issue, I always encourage others to take this simple approach:
-
Define the problem. Problems before requirements, requirements before solutions, solutions before design and design before technology.
-
Gather the data. Don’t try to reinvent the wheel, we live in an age where data is probably already collected somewhere. Locate your source and plan a strategy to gather it.
-
Prepare data for consumption. Once we have the data, we must process, extract and clean it before we can use it.
3.1. Importing libraries
3.2. Meet & greet the data
3.3. The 4 Cs: Correct, complete, create and convert
3.4. Dividing the data into train and test -
Explore the data (EDA). Use statistic methods to find potential problems, patterns, classifications, correlations and computations on the data.
4.1. Effect of multicollinearity
4.2. Pearson’s correlation of coefficient
4.3. Spearman’s correlation of coefficient
4.4. Kendall’s correlation of coefficient -
Model and validate the data. The set of data and expected outcomes will determine which algorithms to use. Choosing a bad model can lead, in the best case, to poor performance and, in the worst case, to a bad conclusion. Also, this step will be used to look for signs of overfitting, under fitting or generalization and to obtain the model’s performance.
5.1. Metrics
5.2. Overfitting and Underfitting
5.3. Cross-validation
5.4. Hyperparameter tunning
5.5. Algorithms
5.6. Defining a methodology -
Optimize. Iterate through the whole process to make it better and more robust.