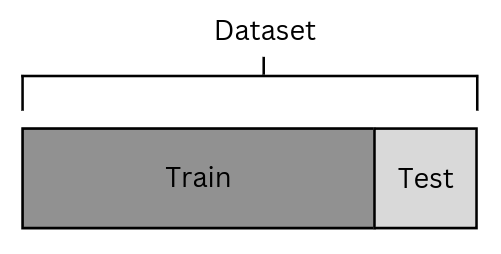
Once the data is prepared, a final step must be taken before starting to create the model: split the data into training and testing. The train data will be used to fit the model and test to get a measure of the quality of our model. The percentage of data used for training will depend entirely on the quantity of data available on our dataset. Consider that having a large percentage of data for training will be good to train the model but will affect validation. On the other hand, a larger data block assigned to the test will affect how the model is adjusted. A good trade-off can be a percentage between 70-90% used for training and the rest for testing. Once the data is divided we must ensure to use the test data only to get a final measure of the quality of our model, using it to get better results may lead to a bad model.
# Sklearn library provides a train_test_split function
from sklearn.model_selection import train_test_split
# divide dataset into train (0.8) and test (0.2)
train_df, test_df = train_test_split(df, test_size=0.2)